Chunking Node
Overview
The Chunking Node is a data processing component that breaks down large text documents into smaller, manageable chunks. This is essential for processing large documents with AI models that have token limits, enabling efficient text analysis and processing.
Node Type Information
| Type | Description | Status |
|---|---|---|
| Batch Trigger | Starts the flow on a schedule or batch event. Ideal for periodic data processing. | ❌ False |
| Event Trigger | Starts the flow based on external events (e.g., webhook, user interaction). | ❌ False |
| Action | Executes a task or logic as part of the flow (e.g., API call, transformation). | ✅ True |
This node is an Action node that processes large text documents and breaks them into smaller chunks for further processing.
Features
Key Functionalities
-
Custom Chunking Logic: Configure specific methodologies and separators to divide text into meaningful units while preserving context.
-
Semantic Preparation: Break data into manageable chunks optimized for vectorization and semantic retrieval processes.
-
Flexible Integration: Incorporate Lamatic.ai's Chunking node into various flow for tailored data processing solutions.
-
Contextual Integrity: Ensure the resulting chunks maintain relevance and logical flow for downstream analysis.
-
Configurable Parameters: Customize chunk size, overlap, and separators to match the needs of your dataset.
Benefits
-
Optimized Data Processing: Enhance the performance of vectorization and semantic retrieval with pre-processed chunks.
-
Scalable Flow: Manage large datasets effectively, enabling flow to scale seamlessly with increasing data.
-
Improved Accuracy: Maintain context and relevance in chunked data for better insights during analysis.
-
Streamlined Automation: Automate text parsing tasks to save time and reduce manual effort.
-
Enhanced Insights: Facilitate meaningful information extraction from structured and unstructured datasets.
What Can You Build?
- Develop a system for efficient text vectorization and semantic retrieval.
- Create flow that handle large datasets by breaking them into manageable chunks.
- Implement automation processes to parse and prepare data for machine learning models.
- Build data processing pipelines that maintain context and relevance through custom chunking methodologies.
Setup
Select the Chunking Node
- Fill in the required parameters.
- Build the desired flow
- Deploy the Project
- Click Setup on the workflow editor to get the automatically generated instruction and add it in your application.
Configuration Reference
| Parameter | Description | Required | Example Value |
|---|---|---|---|
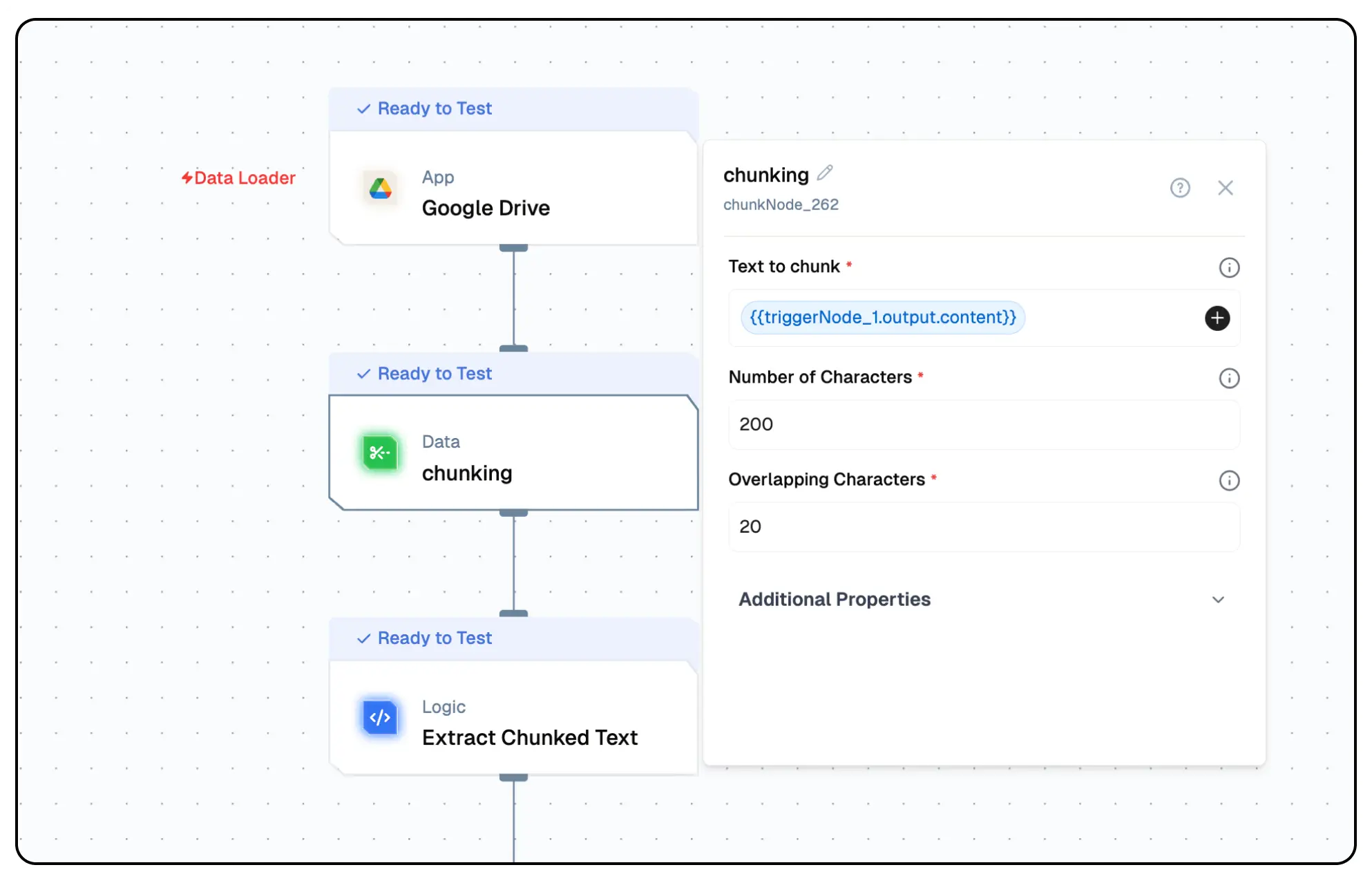
| Text to chunk | The text data to be split into smaller chunks. | Yes | ${{data}} |
| Number of Characters | Max length (in characters) for each chunk. | Yes | 200 |
| Overlapping Characters | Number of characters overlapping between chunks. | Yes | 20 |
| Chunking Type | Choose the method to split the text into chunks. Recursive Character Text Splitter method splits text into smaller chunks while preserving as much context as possible. It works by recursively breaking down the text, starting with larger logical units like paragraphs, then sentences, and so on, until the desired chunk size is achieved. This approach is ideal for use cases where maintaining coherence within chunks is important, such as natural language processing or document indexing. Character Text Splitter is a simpler method that divides text into chunks based on a fixed number of characters. It does not consider the structure of the text, such as paragraphs or sentences, and while it is faster and easier to implement, it may cut off sentences or disrupt the logical flow of the text. | Yes | Recursive Character Text Splitter |
| List of separators | Characters or strings used to define chunk boundaries. | No | \n\n \n |
Low-Code Example
nodes:
- nodeId: chunkNode_262
nodeType: chunkNode
nodeName: chunking
values:
chunkField: "{{triggerNode_1.output.content}}"
numOfChars: 200
separators:
- \n\n
- \n
- " "
chunkingType: recursiveCharacterTextSplitter
overlapChars: "20"
needs:
- triggerNode_1Output
chunks
- An array of objects, each representing a segmented portion of the input text and its associated metadata.
pageContent
- The textual content of the chunk, extracted from the input data.
metadata
- A nested object providing additional details about the chunk's origin or properties.