Memory Add Node
Overview
The Memory Add Node is a data storage component that stores and manages information in memory for use across workflow executions. This node enables persistent data storage and retrieval within workflows.
Node Type Information
| Type | Description | Status |
|---|---|---|
| Batch Trigger | Starts the flow on a schedule or batch event. Ideal for periodic data processing. | ❌ False |
| Event Trigger | Starts the flow based on external events (e.g., webhook, user interaction). | ❌ False |
| Action | Executes a task or logic as part of the flow (e.g., API call, transformation). | ✅ True |
This node is an **Action** node that stores data in memory for persistent use across workflow executions.
Features
Key Functionalities
-
Persistent Storage: Store and manage contextual information that persists across workflow executions.
-
User & Session Management: Support for both user-level and session-specific memory storage with unique identifiers.
-
Metadata Support: Attach additional metadata to stored memories.
Benefits
-
Persistence: Maintain contextual information across multiple workflow executions.
-
Scalability: Efficiently store and retrieve large amounts of contextual data.
-
Flexibility: Support for both user-level and session-level memory storage.
What can I build?
-
Chatbots that remember conversation history and user preferences.
-
Personalized recommendation systems based on user interactions.
-
Knowledge management systems with contextual information retrieval.
Setup
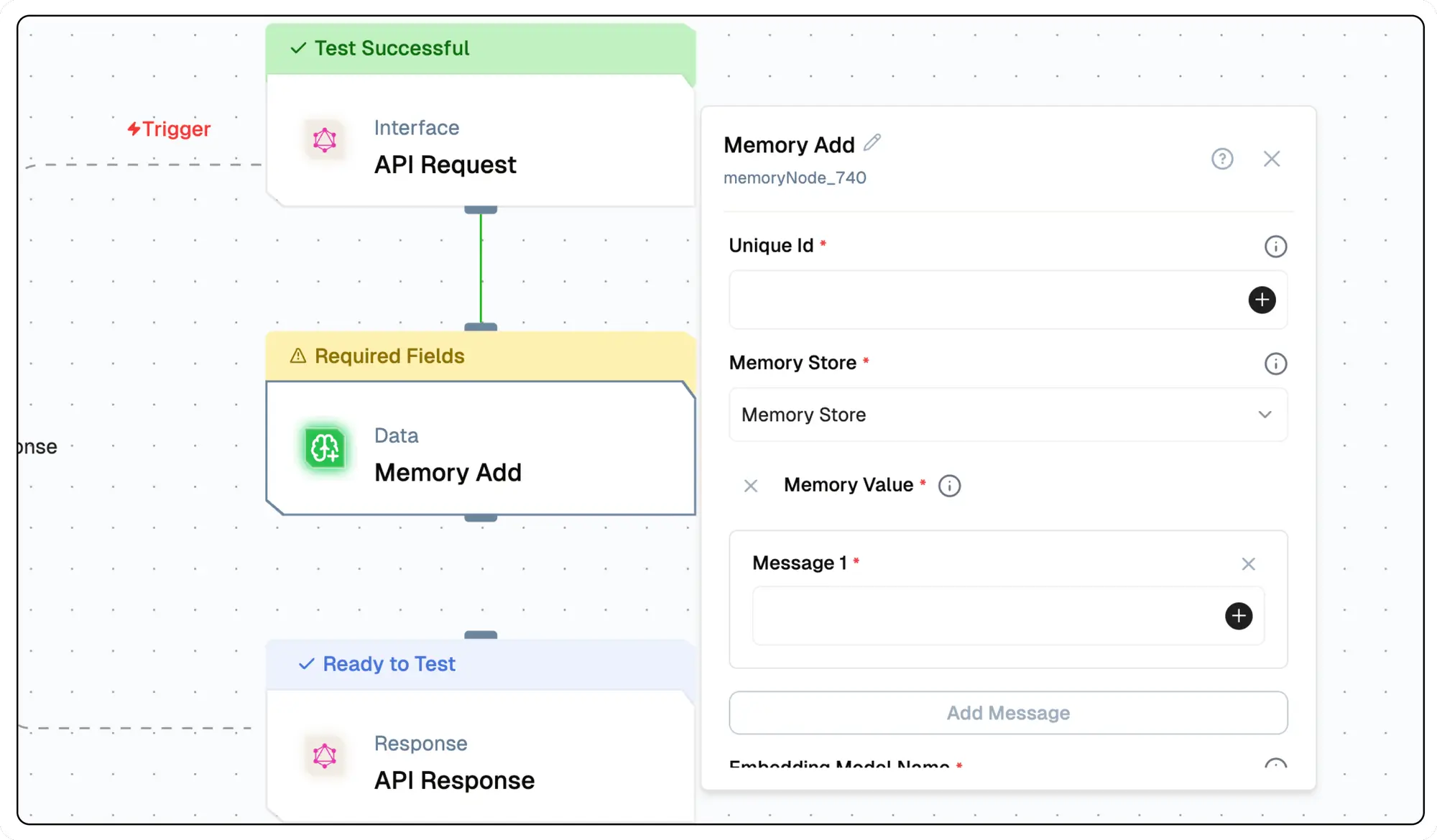
Configure the Memory Node
- Select the Memory Add Node in your workflow.
- Configure the unique user identifier.
- Choose or create a memory collection.
- Set up the embedding and generative models.
- Define optional session ID and metadata.
- Add the Memory Value
- Deploy the project.
Configuration Reference
| Parameter | Description | Example Value |
|---|---|---|
| Unique Id | Identifier for the user whose memory is being stored | 29fcd52e-0813-4fa2-821c-1428a05636ba |
| Session Id | Optional identifier for specific user sessions | 2 (Defaults to Global) |
| Memory Store | The collection where memories will be stored | MemoryStore |
| Memory Value | The actual data from which facts to be retrieved and updated in memory | I like cats |
| Embedding Model Name | Model used for converting text to vectors | text-embedding-ada-002 |
| Generative Model Name | Model used for processing stored information | gpt-3.5-turbo |
| Metadata | Additional JSON data to store with the memory | {"source": "chat"} |
Low-Code Example
- nodeId: memoryNode_858
nodeType: memoryNode
nodeName: Memory Add
values:
uniqueId: '{{triggerNode_1.output.userId}}'
sessionId: ''
memoryValue:
- role: user
content: User likes to watch Pokemon
memoryCollection: finalTest
embeddingModelName:
type: embedder/text
model_name: default
credentialId: some-id
provider_name: openai
credential_name: NEW PROVIDER
generativeModelName:
type: generator/text
model_name: default
credentialId: Some Credential Id
provider_name: openai
credential_name: Testing OpenAIOutput
-memoryActions: An array of objects representing actions or operations performed on the memory, which may be empty if no actions are recorded.
-extractedFacts: An array of strings containing facts or insights derived from the input data and added to the memory.
Example Output
{
"memoryActions": [],
"extractedFacts": [
"User expressed a positive opinion about lamatic."
]
}Common Issues and Debugging
-
Memory Not Being Stored
- Verify the Unique Id is properly configured and not empty
- Check that the Memory Collection name matches exactly across nodes
- Ensure the Memory Value contains valid content.
- Confirm the embedding model is accessible and running
Troubleshooting Steps
-
Check Node Configuration
- Verify all required fields are filled
-
Monitor Workflow Logs
- Look for error messages in the execution logs
- Check for timeout or rate limit errors
-
Test Memory Operations
- Use the workflow testing feature to verify storage
- Confirm immediate retrieval after storage
- Test with simple data before complex implementations