Extract from File Node
Overview
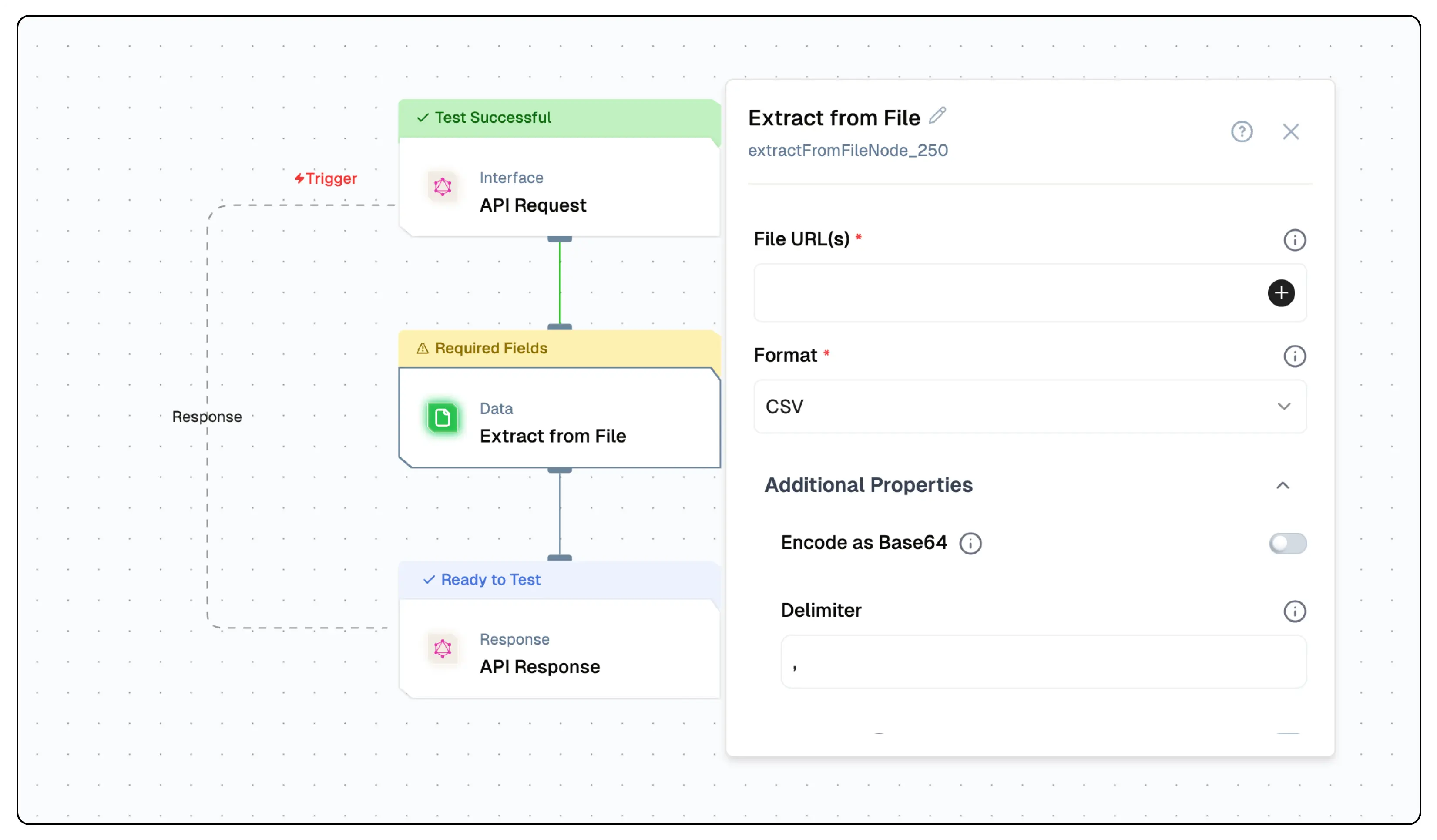
The Extract from File Node is a powerful data extraction component that can process and extract content from various file formats including PDFs, Word documents, text files, and more. This node enables users to convert unstructured file content into structured data for further processing.
Node Type Information
| Type | Description | Status |
|---|---|---|
| Batch Trigger | Starts the flow on a schedule or batch event. Ideal for periodic data processing. | ❌ False |
| Event Trigger | Starts the flow based on external events (e.g., webhook, user interaction). | ❌ False |
| Action | Executes a task or logic as part of the flow (e.g., API call, transformation). | ✅ True |
This node is an Action node that extracts and processes data from various file formats for use in workflows.
Features
Key Functionalities
-
Multiple Format Support: Handles CSV, JSON, Text, HTML, PDF, DOCX, and XLSX files with format-specific parsing options.
-
Configurable Parsing: Offers detailed configuration options for each file type to control how data is extracted and processed.
-
Encoding Options: Supports multiple file encodings including UTF-8, ASCII, and UTF-16LE for text-based formats.
-
Data Transformation: Provides options to clean and transform data during extraction (trimming, filtering, etc.).
-
Base64 Encoding: Supports encoding the extracted data as base64.
Benefits
-
Versatility: Single node solution for handling various file formats commonly used in data processing.
-
Precision Control: Fine-grained control over data extraction through format-specific configuration options.
-
Data Quality: Built-in options for data cleaning and validation during extraction.
-
Seamless Integration: Easy integration with other nodes in the workflow for comprehensive data processing.
What can I build?
- Data processing pipelines that handle multiple file formats
- Automated document parsing systems
- Data extraction flow for business intelligence
- Content aggregation systems from various file sources
- Extract data from files as base64 and use it in AI nodes
Setup
Select the Extract from File Node
- Choose the appropriate operation for your file type
- Configure format-specific parameters
- Provide the file URL
- Deploy and test the extraction
Configuration Reference
Common Parameters
| Parameter | Description | Required | Default |
|---|---|---|---|
| nodeName | Name of the node instance | Yes | "Extract from File" |
| operation | Type of file to extract from | Yes | "extractFromCSV" |
| fileUrl(s) | URL or path to the file/Array of URLs | Yes | "" |
| format | file format | Yes | "auto" |
| encodeAsBase64 | encode the extracted data as base64 of structure: data:content-type;base64,encodedString. Eg: data:text/plain;base64,SW52YWxpZCBwYXJhbWV0ZXJzCg== | No | false |
Format-Specific Parameters
CSV Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| delimiter | The delimiter that will separate columns, usually a comma | No | "," |
| headers | If selected than will return data as list of objects with keys as column names | No | true |
| quote | The character to use to quote fields that contain a ',' delimiter. (e.g. "first,name",last name => ["first,name", "last name"]) | No | """ |
| ignoreEmpty | If true this will discard columns that are all white space or delimiters. | No | false |
| comment | If your CSV contains comments you can use this option to ignore lines that begin with the specified character (e.g. #) | No | null |
| discardUnmappedColumns | If you want to discard columns that do not map to a header. This is only valid in the case when the number of parsed columns is greater than the number of headers. | No | true |
| trim | Trim all white space from columns if true | No | false |
| rtrim | Right trim all columns if true | No | false |
| ltrim | Left trim all columns if true | No | false |
| maxRows | Maximum number of rows to parse. 0 means no limit | No | 0 |
| skipRows | Number of rows to skip at the beginning | No | 0 |
| encoding | Select the encoding of the file | No | "utf8" |
JSON Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| encoding | Select the encoding of the file | No | "utf8" |
Text Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| encoding | Select the encoding of the file | No | "utf8" |
HTML Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| returnRawText | Set to true to return the raw data instead of parsing | No | false |
PDF Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| joinPages | Combine all pages into a single string | No | false |
| password(s) | Password/ Array of Passwords for the PDF file to try from, if the PDF is encrypted | No | "" |
DOCX Configuration
No additional config required
Image Configuration
No additional config required
XLSX Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| ignoreEmpty | Discard empty columns/rows | No | false |
| headers | If selected than will return data as list of objects with keys as column names | No | true |
PDF to Image Configuration
| Parameter | Description | Required | Default |
|---|---|---|---|
| Password(s) | Password for the PDF file, if the PDF is encrypted. You can also send an array of passwords to try. Used for pdf file types. | No | false |
Sample Input
File URL(s): ["https://calibre-ebook.com/downloads/demos/demo.docx","https://example-files.online-convert.com/document/txt/example.txt","https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf"]
Format: Auto Detect
Everything Else DefaultLow-Code Example
nodes:
- nodeId: extractFromFileNode_983
nodeType: extractFromFileNode
nodeName: Extract from File
values:
trim: false
ltrim: false
quote: '"'
rtrim: false
comment: "null"
fileUrl: >-
["https://calibre-ebook.com/downloads/demos/demo.docx","https://example-files.online-convert.com/document/txt/example.txt","https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf"]
headers: true
maxRows: "0"
encoding: utf8
maxPages: "0"
password: ""
skipRows: "0"
delimiter: ","
joinPages: true
format: auto
skipLines: "0"
ignoreEmpty: false
returnRawText: false
discardUnmappedColumns: false
needs:
- triggerNode_1Output
files
- An array of objects, each representing a file and its extracted content along with associated metadata.
metadata
-
A nested object containing descriptive attributes of the file.
mime_type: Specifies the file's MIME type, indicating its format and encoding.type: Categorizes the file's general type.filename: The name of the file.extension: The file's extension.url: The source URL of the file.size: The file size in bytes, ornullif not available.file_id: A unique identifier for the file within the processing context.
data
- An array of strings containing the extracted content from the file.
additional_fields
- A nested object containing supplementary data or metadata about file processing.
raw
-
An array of objects providing unprocessed or detailed extraction data.
metadata: A nested object withinrawdetailing file format and creation metadata.format: The file's format version.title: The file's title.author: The file's author.subject: A description of the file's subject.keywords: Keywords associated with the file.creator: The software or tool used to create the file.producer: The software or library that produced the file.creationDate: The file's creation date.modDate: The file's last modification date.trapped: Related to PDF trapping status.encryption: Indicates the file's encryption status, ornullif not encrypted.
file_path
- A string specifying the temporary or local file path used during processing.
page_count
- An integer indicating the total number of pages in the file.
page
- An integer specifying the page number of the extracted content.
toc_items
- An array containing the table of contents items.
tables
-
An array of objects describing tables extracted from the file.
bbox: An array of coordinates defining the bounding box of a table.rows: The number of rows in a table.columns: The number of columns in a table.
images
- An array of image data extracted from the file.
graphics
- An array of graphic elements extracted from the file.
text
- A string containing the raw text content extracted from a specific page or section.
words
- An array of individual words extracted from the text.
Example Output
"files": [
{
"metadata": {
"mime_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"type": "document",
"filename": "demo.docx",
"extension": "docx",
"url": "https://calibre-ebook.com/downloads/demos/demo.docx",
"size": 1311881,
"file_id": 0
},
"data": [
"data"
]
},
{
"metadata": {
"file_id": 1,
"type": "document",
"url": "https://example-files.online-convert.com/document/txt/example.txt",
"filename": "example.txt",
"extension": "txt",
"mime_type": "text/plain; charset=UTF-8",
"size": null
},
"data": [
"data"
]
}
]Troubleshooting
Common Issues
| Problem | Solution |
|---|---|
| File Not Found | Verify the file URL is accessible and correct |
| Parsing Errors | Check file format matches selected operation |
| Encoding Issues | Try different encoding options for text-based files |
Debugging
- Check file accessibility
- Verify file format matches operation
- Review format-specific configuration
- Check node logs for detailed error messages